





I. Introduction▲
Ce tutoriel a pour but de présenter et comprendre MLlib, l'une des bibliothèques de Machine Learning distribuée de Spark. Cette bibliothèque est très vite devenue l'un des outils indispensables en Data Science, et s'est avérée être une très bonne alternative à R ou Python dès lors que l'on travaille sur de grosses volumétries de données qui ne tiennent plus en mémoire et que l'on souhaite distribuer les calculs sur un cluster de plusieurs machines, avec l'idée fondatrice de porter l'algorithme vers la donnée et non l'inverse.
MLlib n'est pas la première bibliothèque de Machine Learning à pouvoir travailler sur de grandes volumétries. Avant elle, Mahout permettait de le faire en utilisant MapReduce, mais ses limites ont très vite été atteintes. En effet, les algorithmes de Machine Learning sont, par nature, souvent itératifs, avec donc de nombreux passages sur les données. Là où Mahout pèche, c'est que le MapReduce oblige notamment à faire une lecture/écriture sur disque à chaque itération, ce que Spark permet d'éviter grâce à la montée en mémoire des données.
Nous allons donc étudier ici les spécificités de MLlib, à savoir son fonctionnement global, le type de données qu'elle requiert, ainsi que le mode de construction des algorithmes. Ces notions fondatrices vont nous permettre par la suite d'utiliser MLlib de manière optimale.
Les exemples seront montrés via l'API Scala de Spark, mais les concepts s'appliquent tout aussi bien dans les autres langages.
II. Petit rappel de Machine Learning▲
Pour employer de manière efficace MLlib, il est bien entendu nécessaire d'avoir quelques bases en Machine Learning. Le Machine Learning est une branche de l'Intelligence Artificielle qui permet l'analyse et la construction d'algorithmes capables d'apprendre à partir de données d'entrée. On peut distinguer deux catégories principales d'algorithmes : de type supervisé ou non supervisé.
En apprentissage supervisé, on dispose d'un dataset composé de caractéristiques (features) associées à des labels (target). L'objectif est de construire un estimateur capable de prédire le label d'un objet à partir de ses features. L'algorithme apprend alors à partir de données dont on connait le label et est ensuite capable de faire de la prédiction sur de nouvelles données dont on ne connaît pas le label. On distingue les algorithmes de classification, pour lesquels le label à prédire est une classe (prédire un mail comme étant spam/non spam), de ceux de régression, pour lesquels il faut prédire une variable continue (prédire la taille d'une personne en fonction de son poids et de son âge par exemple). En apprentissage non supervisé, on ne dispose pas de label pour nos données. L'objectif est alors de trouver des similarités entre les objets observés, pour les regrouper au sein de clusters.
On peut de plus citer les algorithmes dédiés aux systèmes de recommandation (collaborative filtering), ainsi que l'apprentissage par renforcement, qui regroupent un ensemble d'algorithmes qui vont faire leurs prédictions en apprenant de leurs erreurs au fur et à mesure, et s'adapteront aux éventuels changements.
III. Rapide tour d'horizon de Spark▲
Spark est un framework d'analyse de données né il y a un peu plus de cinq ans à l'AMPLab de l'UC Berkeley. Il est désormais géré par Databricks, entreprise fondée par les développeurs à l'origine du projet. Il est devenu un projet de la fondation Apache en juin 2013 et a obtenu le label « Apache Top-Level Project » en février 2014. Il réunit aujourd'hui plus de 200 contributeurs venant de plus de 50 entreprises telles que Yahoo ! ou Intel. Spark s'est appuyé sur le framework Hadoop, déjà existant et très utilisé, en utilisant le système de fichiers distribués de ce dernier, HDFS, et le gestionnaire de ressources YARN, permettant d'exécuter des programmes Spark sur Hadoop. Cependant, à la différence d'Hadoop, Spark ne se limite pas au paradigme MapReduce et promet des performances jusqu'à 100 fois plus rapides. L'origine de ces performances : la montée en mémoire. Là où Hadoop lit les données sur des disques durs, Spark peut les monter en mémoire et gagner ainsi énormément en rapidité.
III-A. Les API et les projets attenants▲
Spark possède trois API : en Scala, Python et Java. Pour les deux premiers langages, il propose une interface en ligne de commande qui permet une exploration rapide et interactive des données. La version 1.4 de Spark prévue pour juin 2015 inclura en plus une API R. Plusieurs projets se greffent au-dessus de Spark : Spark SQL qui permet d'exécuter des requêtes SQL sur des RDD (Résilient Distributed Datasets) et contient l'API des DataFrames (collection de données organisées en colonnes, très utilisé en Data Science), Spark Streaming pour l'analyse de données en temps réel, GraphX pour l'exécution d'algorithmes de graphes et donc MLlib, la bibliothèque de machine learning.
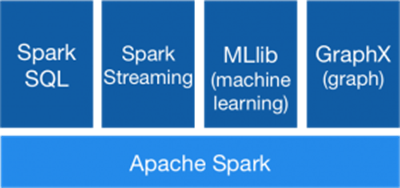
III-B. Les Resilient Distributed Datasets▲
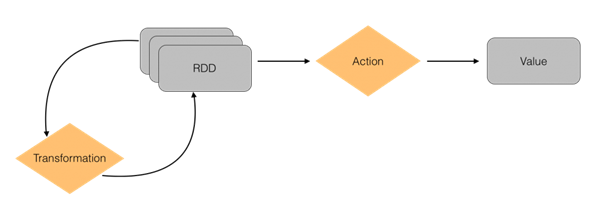
Le Resilient Distributed Dataset (RDD) est un concept créé par les fondateurs de Spark. C'est sous ce format que sont gérées les données en Spark. Les RDD sont des collections immutables. Par défaut, lors de la lecture d'un fichier, les données sont manipulées sous forme d'un RDD de String où chaque élément correspond à une ligne du fichier. Il est ensuite possible d'effectuer des opérations sur le RDD. Il en existe deux sortes :
- les transformations : elles transforment un RDD en un autre RDD (map, filter, reduceByKey) ;
- les actions : elles transforment un RDD en une valeur (count, collect…).
Il est important de noter que les transformations sont « lazy », c'est-à-dire que Spark n'exécutera les calculs demandés que si une action est appliquée à un RDD.
Dans cette présentation, nous allons principalement présenter MLlib via l'API Scala, qui est l'API de base. Cependant, les utilisateurs des autres API pourront facilement s'y retrouver, car l'utilisation de la bibliothèque est relativement semblable pour tous les langages. Nous considérons de plus que l'utilisateur possède déjà une connaissance minimale de Spark et des RDD, l'objectif étant de les utiliser dans MLlib.
IV. MLlib: Une bibliothèque optimisée pour le calcul parallélisé▲
MLlib est la bibliothèque de Machine Learning de Spark. Tous les algorithmes de cette bibliothèque sont conçus de manière à être optimisés pour le calcul en parallèle sur un cluster. Une des conséquences directes à cela est que, pour de petits datasets qui tiennent en mémoire, un algorithme lancé depuis Spark en local sur votre machine mettra beaucoup plus de temps à s'exécuter que le même algorithme lancé depuis Python ou R, qui sont optimisés pour le mode local. En revanche, les performances deviennent extrêmement intéressantes lorsque les volumétries sont très importantes.
MLlib a été conçu pour une utilisation très simple des algorithmes en les appelant sur des RDD dans un format spécifique, quel que soit l'algorithme choisi. L'architecture se rapproche ainsi de ce que l'on trouve dans la bibliothèque scikit-learn de Python, bien qu'il y ait encore des différences notables qui vont être effacées dans les prochaines versions de l'API.
Les algorithmes présents dans MLlib sont, tout comme le reste du framework, développés en Scala, en se basant principalement sur le package d'algèbre linéaire Breeze pour l'implémentation des algorithmes. De plus, pour faire fonctionner MLlib, il est nécessaire d'installer gfortran, ainsi que Numpy si vous utilisez l'API Python.
V. Les types de données spécifiques à MLlib▲
L'une des spécificités de MLlib (et peut-être une de ses faiblesses pour le moment) est qu'il nous contraint à utiliser des RDD aux types spécifiques. Les algorithmes implémentés nécessitent ainsi en entrée des RDD[Vector] (pour des données n'ayant pas de label), des RDD[LabeledPoint] (spécifiques à l'apprentissage supervisé) ou bien des RDD[Rating] (pour les systèmes de recommandation).
V-A. Vector▲
Les Vector sont de simples vecteurs de doubles. MLlib supporte deux types de Vector : dense (chaque entrée doit être spécifiée) et sparse (seules les entrées non nulles, avec leurs positions, doivent être spécifiées).
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// Create a dense vector (1.0, 0.0, 3.0).
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries.
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))Contrairement à ce que son nom peut sembler indiquer, l'objet Vector ne donne accès à aucune opération arithmétique quand ils sont utilisés en Scala ou en Java. Il correspond simplement à une représentation particulière de la donnée afin d'uniformiser l'utilisation des algorithmes.
V-B. LabeledPoint▲
Ce type de donnée est spécifique aux algorithmes d'apprentissage supervisé, pour lesquels il est nécessaire de spécifier le label correspondant à chaque vecteur pour la phase d'apprentissage. Un LabeledPoint est composé d'un vecteur, dense ou sparse, associé à un label.
Le label est obligatoirement un double, ce qui permet d'utiliser à la fois des algorithmes de classification ou de régression. Pour la classification, le label doit obligatoirement prendre comme valeurs 0, 1, 2, 3… en commençant toujours par 0.
Une fois en présence d'un LabeledPoint, il est possible d'accéder au label correspondant via l'attribut .label, ainsi qu'au Vector via l'attribut .features.
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
// Create a labeled point with a positive label and a dense feature vector.
val pos: LabeledPoint = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// Create a labeled point with a negative label and a sparse feature vector.
val neg: LabeledPoint = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
// Get the label and the features corresponding to the LabeledPoint
val label: Double = neg.label
val features: Vector = neg.featuresV-C. Rating▲
Une donnée de type Rating est exclusivement utilisée dans le cadre du collaborative filtering, qui est un algorithme utilisé classiquement dans les systèmes de recommandation. Un Rating n'est autre qu'un tuple contenant trois éléments :
- User : un entier représentant un utilisateur ;
- Item : un entier représentant un item ;
- Rating : un double représentant la note qu'a donnée User à Item.
Dans les prochaines versions de Spark, ces contraintes sur les types de données vont être relâchées. Les algorithmes prendront alors en entrée des DataFrames, introduites dans la version 1.3, ce qui les rapprochera encore plus du fonctionnement rencontré sous Python ou R.
VI. L'architecture des algorithmes▲
VI-A. Les algorithmes▲
Que ce soit pour de la classification, de la régression, du clustering ou autre, tous les algorithmes possèdent leur propre classe (voire plusieurs selon leur type d'implémentation). La démarche est alors la suivante :
- instancier la classe ;
- appeler les setters associés pour modifier les paramètres (qui sont relatifs à l'algorithme en question) ;
- appeler la méthode run() sur un RDD pour entraîner le modèle.
Cependant, pour de nombreux algorithmes (souvent les principaux utilisés), il est aussi possible d'utiliser des méthodes statiques au lieu de la classe avec les setters. Il suffit alors d'appeler la méthode train() contenue dans l'Object associé à l'algorithme qui prend comme entrées un RDD, ainsi que tous les paramètres nécessaires. Cette manière de faire est beaucoup plus proche des implémentations classiques en Python ou R, et est donc à prioriser lorsque c'est possible.
Dans tous les cas, une fois que l'algorithme est entraîné, il retourne un objet « Model ».
L'API Java a exactement le même fonctionnement que celui en Scala pour la construction des algorithmes. En Python, on utilise systématiquement la méthode train().
VI-B. Les classes Model▲
Chaque algorithme de MLlib, une fois entraîné sur des données, retourne un objet Model, qui va typiquement posséder une méthode predict(). Cette méthode va permettre d'appliquer le modèle à une nouvelle donnée ou un nouveau RDD de données pour prédire une valeur.
Prenons l'exemple de la Régression Logistique, qui est un algorithme de classification binaire qui identifie un hyperplan séparant au mieux les deux classes. L'algorithme va donc prendre en entrée un RDD[LabeledPoint] et retourner un LogisticRegressionModel qui va pouvoir prédire la classe de nouvelles données grâce à sa méthode predict(), comme le montre le schéma ci-dessous.

VII. Construire une chaîne de traitement de données en MLlib▲
En pratique, la démarche globale pour construire un pipeline de traitement de données en MLlib est la suivante :
- chargement des données à traiter dans un RDD ;
- transformation des données pour obtenir un RDD[Vector] ou un RDD[LabeledPoint] utilisable par un algorithme de MLlib.
Cette étape est plus généralement appelée Feature Engineering. Elle regroupe tout le travail de nettoyage, de gestion des outliers et des données manquantes et de création de nouvelles features, puis de transformation au bon format de RDD requis par MLlib. Cette partie est la plus longue et à la fois la plus intéressante de la démarche en Data Science, car elle implique une réflexion sur la signification des données et permet, lorsqu'elle est pertinente, d'améliorer grandement les performances des algorithmes ;
- sélection et entraînement d'un algorithme à l'aide des méthodes run() ou train() sur le RDD créé ;
- prédictions sur de nouvelles données grâce à la méthode predict() du Model résultant de l'étape précédente.
Dans le cas d'application de modèles supervisés (classification ou régression), une étape supplémentaire est fortement recommandée avant l'entraînement de l'algorithme : la séparation du RDD en train et test sets. L'algorithme va alors être entraîné uniquement sur le train set, alors que le test set va être utilisé afin de valider les performances du modèle créé (le test set correspond alors à des « nouvelles données », au sens où l'algorithme ne les a pas utilisées pour s'entraîner, dont on connaît la véritable valeur que l'on souhaite prédire). Cela permet notamment de tuner les paramètres pour améliorer les capacités de généralisation de l'algorithme à de nouvelles données.
La figure ci-dessous illustre la démarche complète de création d'un pipeline de traitement de données dans le cas d'un apprentissage supervisé.

Dans un cas non supervisé (classiquement pour des tâches de clustering), nous n'avons pas de notion de variable à prédire. On utilise donc un RDD de Vector, et l'apprentissage se fait sur toutes les données disponibles, sans l'étape de splitting.
VII-A. Remarque sur la taille des datasets▲
Il n'est cependant pas rare que le dataset sur lequel on souhaite entraîner l'algorithme ne soit pas très volumineux. Il peut en effet arriver d'être en possession d'une volumétrie très importante de données brutes qui nécessitent un prétraitement en Spark (fichiers de logs par exemple), et qu'une fois ce traitement effectué, les données agrégées puissent passer en mémoire. Il est alors recommandé de passer à une bibliothèque optimisée pour le calcul sur un seul nœud.
Il est notamment très facile de jongler de la sorte si vous utilisez l'API Python de Spark, appelée PySpark. Utiliser PySpark pour tous les prétraitements sur les grosses volumétries jusqu'à obtenir un dataset qui tienne en mémoire, puis transformer le RDD en Data Frame Pandas ou en Array Numpy et utiliser scikit-learn. De même, si vous cherchez à faire un grid-search pour tester différents paramètres pour un même algorithme, il peut être intéressant de faire un parallelize() sur la liste de paramètres et d'utiliser une bibliothèque comme scikit-learn sur chaque nœud lorsque la volumétrie le permet. Si cependant la volumétrie après traitement de la donnée reste trop importante, alors MLlib est de loin le plus adapté.
VIII. Conclusion▲
Maintenant que les concepts fondamentaux liés à MLlib sont acquis, nous sommes prêts à l'utiliser de manière efficace et claire. Dans un autre tutoriel, nous présenterons les principaux packages présents dans MLlib pour utiliser des algorithmes de Machine Learning, et donnerons de nombreux exemples pratiques d'utilisation.
IX. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société Xebia qui est un cabinet de conseil parisien spécialisé dans les technologies Big Data, Cloud, Web, les architectures Java et mobilité dans les environnements agiles.
Nous tenons à remercier Claude Leloup pour sa correction orthographique et Mickael Baron pour la mise au gabarit.