





I. Introduction▲
Cet article correspond à la deuxième partie de l'étude de MLlib, l'une des principales bibliothèques de Machine Learning distribuées de Spark. Les concepts principaux liés à cette bibliothèque ayant été préalablement présentés, l'objectif de cet article est de mettre en pratique ces concepts à travers plusieurs exemples d'utilisation des différents algorithmes qui composent MLlib.
MLlib est composé de plusieurs packages, qui représentent tous soit une catégorie spécifique d'algorithmes de Machine Learning (classification, régression, clustering, recommandation, etc.), soit des outils nécessaires à leurs usages (feature engineering, statistiques, etc.). Nous allons maintenant passer en revue quelques-uns des principaux packages disponibles et fournir des exemples d'utilisation et d'implémentation.
Les exemples seront montrés via l'API Scala de Spark, mais les concepts s'appliquent tout aussi bien dans les autres langages.
II. La création et l'analyse exploratoire des données avec les packages random et stat▲
II-A. Le package random▲
MLlib permet la génération aléatoire de RDDs via son package random. C'est un package très utile pour faire des tests, nous permettant de créer des données selon plusieurs types de distributions : Normale, Poisson, Exponentielle, Log-Normale, Gamma et Uniforme. Utilisons ce package pour créer un RDD[Vector], contenant un million de lignes et quatre colonnes, avec des données tirées selon une loi normale centrée réduite. On utilisera ce RDD par la suite pour présenter les différents algorithmes de Machine Learning (les résultats des algorithmes ne seront pas très bons, car les données n'ont aucune structure, l'idée étant simplement de présenter comment construire une chaîne de traitement en Machine Learning).
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.random.RandomRDDs
import org.apache.spark.rdd.RDD
// Create a RDD[Vector] with data drawn from normal distribution
val data: RDD[Vector] = RandomRDDs.normalVectorRDD(sc, numRows = 1000000L, numCols = 4)II-B. Le package stat▲
Le package stat regroupe dans son objet Statistics des fonctions statistiques très utilisées, notamment dans la partie exploratoire des données. On peut citer par exemple la fonction colStats() qui retourne une instance de MultiVariateStatisticalSummary regroupant entre autres les max, min, mean et variance pour chaque colonne d'un RDD[Vector].
2.
3.
4.
5.
6.
7.
8.
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
// Compute column summary statistics.
val summary: MultivariateStatisticalSummary = Statistics.colStats(data)
println(summary.mean) // a dense vector containing the mean value for each column
println(summary.variance) // column-wise variance
println(summary.max) // highest number for each column
Appliquées au RDD généré dans l'étape précédente, on devrait retrouver des valeurs proches de 0 pour la moyenne et de 1 pour la variance.
On trouve de plus une fonction de calcul de la corrélation entre deux RDD. Les corrélations supportées sont celles de Pearson et de Spearman. Si on ne spécifie qu'un seul RDD, la fonction calcule l'autocorrélation.
2.
3.
4.
5.
6.
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.stat.Statistics
// Calculate the correlation matrix using Pearson's method. Use "spearman" for Spearman's method.
// If a method is not specified, Pearson's method will be used by default.
val correlMatrix: Matrix = Statistics.corr(data, "pearson")
Pour notre RDD, la matrice retournée doit donner des 1 sur la diagonale, et des valeurs proches de 0 sur le reste (pas de corrélation entre les différentes colonnes).
Pour compléter ce panel, on trouve aussi des fonctions relatives aux tests d'hypothèses, comme le test du chi-deux (chiSqTest).
III. Les algorithmes d'apprentissage supervisé avec les packages classification et regression▲
Comme leurs noms l'indiquent, les packages classification et regression regroupent tous les principaux algorithmes liés à l'apprentissage supervisé (voir le précédent article sur MLlib pour un rappel sur le Machine Learning) et vont donc demander l'utilisation de RDD[LabeledPoint]. Les deux types ont pour objectif de prédire une variable grâce à des features en utilisant un training set contenant les vrais labels. La différence entre les deux est qu'en classification, on cherche à prédire une variable discrète (ex: spam / non spam), alors qu'elle est continue en régression. Voyons maintenant comment sont utilisés quelques algorithmes classiques de Machine Learning présents dans ces packages.
III-A. Un exemple en régression : LinearRegressionWithSGD▲
La régression linéaire est l'algorithme le plus classique pour des problématiques de régression. En MLlib, il est implémenté en utilisant de la Descente de Gradient Stochastique, d'où son nom. Son objectif est de minimiser la fonction de coût suivante :
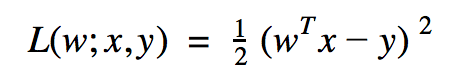
Avec :
- w le vecteur des paramètres appris par l'algorithme (correspondant globalement au poids de chaque caractéristique) ;
- x un vecteur de caractéristiques (un point dans l'espace) ;
- y la valeur réelle observée.
Il est possible d'y ajouter des termes de régularisation, donnant lieu aux algorithmes dits de Ridge Regression ou de Lasso.
Voici un exemple d'implémentation, utilisant comme données d'entrée le RDD créé précédemment. Un autre RDD nommé label est aussi créé, il va représenter notre variable cible. Il est créé selon une loi uniforme (double entre 0 et 1).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.random.RandomRDDs
import org.apache.spark.mllib.regression.{LinearRegressionWithSGD, LinearRegressionModel, LabeledPoint}
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.rdd.RDD
// Create a RDD[Vector] with data drawn from normal distribution
val data: RDD[Vector] = RandomRDDs.normalVectorRDD(sc, numRows = 1000000L, numCols = 4)
// Create a RDD of labels for regression
val label: RDD[Double] = RandomRDDs.uniformRDD(sc, 1000000L)
// Create a RDD[LabeledPoint]
val dataWithLabel: RDD[LabeledPoint] = data.zip(label).map(point => LabeledPoint(point._2, point._1))
dataWithLabel.cache()
// Building the model
val numIterations = 100
val model: LinearRegressionModel = LinearRegressionWithSGD.train(dataWithLabel, numIterations)
// Evaluate model on training examples
val predictionAndLabels: RDD[(Double, Double)] = dataWithLabel.map { case LabeledPoint(label, features) =>
val prediction: Double = model.predict(features)
(prediction, label)
}
// Compute Mean Square Error
val metrics: RegressionMetrics = new RegressionMetrics(predictionAndLabels)
val MSE = metrics.meanSquaredError
println("training Mean Squared Error = " + MSE)
La démarche est classique, et on la retrouvera quasiment systématiquement :
- création du RDD sous le bon format ;
- construction et entraînement du modèle ;
- prédiction et évaluation des prédictions faites.
On remarquera que l'on a préféré la méthode train() de LinearRegressionWithSGD en mettant le nombre d'itérations en paramètre de la méthode, plutôt que d'utiliser la méthode run() avec son setter associé. De plus, il est fortement recommandé d'utiliser la méthode cache() pour monter notre RDD en mémoire. De nombreux algorithmes de Machine Learning nécessitent plusieurs itérations sur les données, leur montée en mémoire va donc réduire fortement le temps de calcul.
Pour les algorithmes de régression, il est possible d'évaluer les modèles à l'aide de la classe RegressionMetrics, qui permet d'obtenir notamment la mean squared error.
III-B. Un exemple en classification : LogisticRegressionWithLBFGS▲
Contrairement à ce que son nom peut sembler l'indiquer, la régression logistique est un algorithme de classification utilisé fréquemment pour prédire une réponse (binaire ou multiclasses). La fonction de coût qu'il veut minimiser est la suivante :
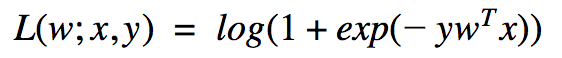
Son implémentation en MLlib se fait soit par Descente de Gradient Stochastique (LogisticRegressionWithSGD) ou par l'algorithme Limited-Memory Broyden-Fletcher-Goldfarb-Shanno (LogisticRegressionWithLBFGS), qui est généralement préféré. Cette dernière implémentation ne possède pas de méthode train(), nous aurons donc recours à la méthode run() et à l'appel des setters associés à la classe.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS}
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.random.RandomRDDs
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.rdd.RDD
// Create a RDD[Vector] with data drawn from normal distribution
val data: RDD[Vector] = RandomRDDs.normalVectorRDD(sc, numRows = 1000000L, numCols = 4)
// Create a RDD of labels for classification (5 classes)
val label: RDD[Double] = RandomRDDs.uniformRDD(sc, 1000000L).map(x => (x*5).floor)
// Create a RDD[LabeledPoint]
val dataWithLabel: RDD[LabeledPoint] = data.zip(label).map(point => LabeledPoint(point._2, point._1))
// Split data into training (75%) and test (25%).
val splits: Array[RDD[LabeledPoint]] = dataWithLabel.randomSplit(Array(0.75, 0.25), seed = 11L)
val training: RDD[LabeledPoint] = splits(0).cache()
val test: RDD[LabeledPoint] = splits(1)
// Run training algorithm to build the model
val model: LogisticRegressionModel = new LogisticRegressionWithLBFGS().setNumClasses(10).run(training)
// Compute raw scores on the test set
val predictionAndLabels: RDD[(Double, Double)] = test.map { case LabeledPoint(label, features) =>
val prediction: Double = model.predict(features)
(prediction, label)
}
// Get evaluation metrics
val metrics: MulticlassMetrics = new MulticlassMetrics(predictionAndLabels)
val precision: Double = metrics.precision
println("Precision = " + precision)
La démarche appliquée est la même que dans l'exemple précédent, avec en plus une étape de découpage du RDD, ce qui est recommandé en apprentissage supervisé. L'apprentissage se fait alors sur le training set, et les prédictions et évaluations se font sur le test set. Cela permet d'avoir une meilleure idée de la capacité de généralisation de notre algorithme à de nouvelles données sur lesquelles il ne s'est pas entraîné.
Pour les algorithmes de classification, il est possible d'évaluer les modèles à l'aide de la classe MulticlassMetrics (dans le cas où il y a plus de deux classes), qui permet d'obtenir notamment la précision ou la matrice de confusion. Pour une classification binaire, il faut plutôt utiliser BinaryClassificationMetrics, qui a un fonctionnement similaire, mais possède des métriques supplémentaires spécifiques à ce type de classification.
III-C. Autres algorithmes▲
Voici quelques autres algorithmes présents dans les packages classification et regression :
III-C-1. Classification▲
- NaiveBayes : algorithme qui suppose l'indépendance de chaque caractéristique du jeu de données pour faciliter le calcul de probabilité d'appartenance à une classe. Il est par exemple utilisé dans la classification de spams.
- SVMWithSGD : c'est une généralisation des classifieurs linéaires plus classiques. Il donne souvent de bons résultats en pratique et est particulièrement utilisé lorsqu'il faut travailler avec des données à grandes dimensions. Il a de plus l'avantage de ne nécessiter qu'un faible nombre d'hyperparamètres (les paramètres qu'il faut régler pour améliorer les résultats de l'algorithme).
III-C-2. Régression▲
- LassoWithSGD : algorithme de régression linéaire pour lequel on ajoute une pénalisation du premier ordre (on ajoute la somme des valeurs absolues des paramètres à la fonction de coût) pour faire de la régularisation et rendre l'algorithme plus robuste et moins enclin à de l'overfitting (apprentissage par cœur du training set).
- RidgeRegressionWithSGD : identique au précédent, mais la pénalisation est cette fois du second ordre (on ajoute la somme du carré des paramètres à la fonction de coût).
Leur utilisation se fait exactement de la même manière que pour les deux algorithmes précédemment présentés. Il suffit de regarder dans la documentation les différents paramètres qui leur sont propres.
IV. Le package tree pour les algorithmes fonctionnant à la fois en régression et en classification▲
Les algorithmes basés sur des arbres de décision (DecisionTree, GradientBoostedTree, RandomForest) pouvant être utilisés à la fois en classification et en régression, ils bénéficient d'un package tree qui leur est propre. Ils permettent de plus d'utiliser des variables catégorielles (il faut alors spécifier à l'algorithme quelles sont les variables catégorielles en question).
DecisionTree est un algorithme très commun en Machine Learning, car il est très interprétable et n'oblige pas à faire un positionnement préalable des données. Concrètement, cet algorithme fonctionne en pratiquant de manière récursive des partitions binaires dans l'espace des caractéristiques. À chaque étape de découpage, l'algorithme va choisir la caractéristique qui va maximiser le gain en information après la coupure, c'est-à-dire minimiser notre incertitude sur la variable à prédire dans les sous-ensembles créés.
RandomForest et GradientBoostedTree sont des méthodes dites d'ensemble. Le principe n'est plus de construire un unique arbre de décision, mais un ensemble, soit en parallèle (RandomForest), soit les uns après les autres sur les résidus des précédents (GradientBoostedTree). Ce sont des algorithmes très puissants, donnant souvent de très bons résultats.
En plus de la méthode classique run(), il est possible pour les algorithmes DecisionTree et RandomForest d'utiliser les méthodes trainClassifier() ou trainRegressor(), qui ont des paramètres différents. Voici un exemple de classification avec un DecisionTree.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.random.RandomRDDs
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.rdd.RDD
// Create a RDD[Vector] with data drawn from normal distribution
val data: RDD[Vector] = RandomRDDs.normalVectorRDD(sc, numRows = 1000000L, numCols = 4)
// Create a RDD of labels for classification
val label: RDD[Double] = RandomRDDs.uniformRDD(sc, 1000000L).map(x => (x*5).floor)
// Create a RDD[LabeledPoint]
val dataWithLabel: RDD[LabeledPoint] = data.zip(label).map(point => LabeledPoint(point._2, point._1))
// Split data into training (75%) and test (25%).
val splits: Array[RDD[LabeledPoint]] = dataWithLabel.randomSplit(Array(0.75, 0.25), seed = 11L)
val training: RDD[LabeledPoint] = splits(0).cache()
val test: RDD[LabeledPoint] = splits(1)
// Train a DecisionTree model
val model: DecisionTreeModel = DecisionTree.trainClassifier(training, numClasses = 5,
categoricalFeaturesInfo = Map[Int, Int](), impurity = "gini", maxDepth = 5, maxBins = 32)
// Evaluate model on test instances
val predictionAndLabels: RDD[(Double, Double)] = test.map { point =>
val prediction = model.predict(point.features)
(prediction, point.label)
}
// Get evaluation metrics
val metrics: MulticlassMetrics = new MulticlassMetrics(predictionAndLabels)
val precision: Double = metrics.precision
println("Precision = " + precision)
println("Learned classification tree model:\n" + model.toDebugString)
Les autres algorithmes fonctionnent globalement de la même manière, à la différence près que les paramètres à régler sont plus nombreux. Pour le GradientBoostedTree, le choix entre régression et classification ne se fait pas avec trainRegressor ou trainClassifier, mais en utilisant la classe BoostingStrategy et en spécifiant defaultParams("Classification") ou defaultParams("Regression"). Les autres paramètres sont aussi à spécifier de cette manière.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
import org.apache.spark.mllib.tree.GradientBoostedTrees
import org.apache.spark.mllib.tree.configuration.BoostingStrategy
val boostingStrategy = BoostingStrategy.defaultParams("Classification")
boostingStrategy.numIterations = 3 // Note: Use more iterations in practice.
boostingStrategy.treeStrategy.numClassesForClassification = 2
boostingStrategy.treeStrategy.maxDepth = 5
// Empty categoricalFeaturesInfo indicates all features are continuous.
boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]()
val model = GradientBoostedTrees.train(training, boostingStrategy)
V. L'apprentissage non supervisé avec le package clustering▲
Le package clustering contient une liste d'algorithmes de type non supervisé, pour lesquels l'objectif n'est plus de prédire une variable, mais de regrouper des points dans les clusters à forte similarité. On utilise alors des RDD[Vector] puisqu'il n'y a aucun label à disposition. Les algorithmes de clustering sont couramment utilisés dans de l'analyse exploratoire de données ou bien comme composante d'une pipeline pour l'utilisation d'un algorithme supervisé.
K-Means est l'algorithme de clustering le plus couramment utilisé. Il est nécessaire de lui spécifier en paramètre le nombre de clusters que l'on souhaite trouver, ce qui en fait parfois sa faiblesse. Son utilisation, comme celle de tous les autres algorithmes de Machine Learning avec MLlib, est très simple.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
import org.apache.spark.mllib.clustering.{KMeansModel, KMeans}
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.random.RandomRDDs
import org.apache.spark.rdd.RDD
// Create a RDD[Vector] with data drawn from normal distribution
val data: RDD[Vector] = RandomRDDs.normalVectorRDD(sc, numRows = 1000000L, numCols = 4)
// Cluster the data into two classes using KMeans
val clusters: KMeansModel = KMeans.train(data, k = 2, maxIterations = 20)
// Evaluate clustering by computing Within Set Sum of Squared Errors
val WSSSE: Double = clusters.computeCost(data)
println("Within Set Sum of Squared Errors = " + WSSSE)
Comme on peut le voir dans le code ci-dessus, le KMeansModel possède une méthode computeCost qui calcule la somme du carré des distances entre chaque point et son centroïde le plus proche. C'est une mesure de la similarité des points au sein de chaque cluster.
VI. Les autres packages▲
Voici quelques autres packages présents dans la version 1.3 de Spark MLlib, que nous n'allons pas développer ici, mais qui sont facilement utilisables et compréhensibles via leurs documentations associées.
- feature : ce package contient différentes classes relatives au Feature Engineering. On y trouve des algorithmes tels que TF-IDF qui permettent de construire des features à partir de textes, ou bien StandardScaler qui permet de mettre les features à la même échelle (souvent requis par les algorithmes de Machine Learning).
- linalg : ce package est utilisé pour représenter des matrices, ainsi que pour faire de la Réduction de Dimension.
- optimization : ce package permet d'avoir accès aux algorithmes tels que la Descente de Gradient Stochastique pour des développements plus poussés. C'est sur ce package que se basent beaucoup d'algorithmes de Machine Learning présentés précédemment.
- recommendation : c'est dans ce package que se trouvent les algorithmes relatifs au Collaborative Filtering (pour les systèmes de recommandation).
VII. MLlib: Quel avenir?▲
On l'a vu, MLlib permet de déployer des chaînes de traitement de données de manière relativement simple sur Spark. La bibliothèque répond de manière forte aux réclamations faites contre Mahout pour les problématiques de Machine Learning sur des Big Datas.
La bibliothèque est en constante expansion, avec l'ajout fréquent de nouveaux algorithmes et de nouvelles méthodes de traitement des features.
Cependant, MLlib souffre de quelques critiques, que leurs concepteurs sont en train d'effacer avec brio. L'une des principales critiques est que, comme on l'a vu, beaucoup d'algorithmes peuvent à la fois être entraînés grâce à la méthode run() et à la méthode train(), ce qui porte parfois à confusion. De plus, l'utilisateur est obligé de passer systématiquement par une étape de mise en correspondance des données pour les mettre au format souhaité (RDD[Vector] ou RDD[LabeledPoint]), alors qu'une bibliothèque telle que scikit-learn en Python est beaucoup plus flexible en acceptant notamment des Arrays Numpy ou bien des DataFrames Pandas.
C'est avec l'objectif de contrer ces problèmes que les développeurs du projet ont proposé une nouvelle API en parallèle à Mllib : Spark ML. Cette bibliothèque, initiée depuis la version 1.2 de Spark, propose une structure plus logique pour la construction des algorithmes de Machine Learning, incorporant notamment des notions essentielles en Data Science que sont les Pipelines et la Cross Validation. Le fait qu'elle s'inspire de bibliothèques qui ont fait leurs preuves, telles que scikit-learn en Python, lui permet de gagner de plus en plus de crédit, grâce notamment au fait de pouvoir prendre en entrée des DataFrames, notion introduite dans la version 1.3 de Spark SQL.
VIII. Conclusion▲
Si vous souhaitez travailler plus en profondeur sur les notions présentées sur MLlib, nous vous conseillons de jeter un œil aux ateliers Hands'On que nous avons donnés cette année à Devoxx France et à Mix-IT sur le même sujet. Les répertoires associés se trouvent aux adresses suivantes :
IX. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société Xebia qui est un cabinet de conseil parisien spécialisé dans les technologies Big Data, Cloud, Web, les architectures Java et mobilité dans les environnements agiles.
Nous tenons à remercier ced pour sa correction orthographique et Mickael Baron pour la mise au gabarit.